Transcribing Flemish

Transcribing Flemish
Let our tool write your meeting notes, for you.
Us humans aren't very good at multitasking. Writing concise, straightforward notes you can still get your head around. It requires a certain set of skills almost nobody seems to possess.
There's already plenty of transcription models out there. Think Whisper, AssemblyAI and Google Cloud Speech-To-Text. They're all great, but none of them are particularly good at Flemish (Vlaams), let alone West-Flemish (West-Vlaams).
Step 1: Doing some benchmarks
First steps to setup get started is to get a clear visualization of how the current models perform. We prepared a dataset combined of the validation sets of mozilla-foundation/common_voice_17_0, google/fleurs, facebook/voxpopuli and our own recordings of West-Flemish.
Leading up to a validation set of 19.252 recordings.
We calculated the performance a couple of models using two metrics:
WER (Word Error Rate): This is a common metric used to evaluate the accuracy of speech recognition systems. It measures the percentage of words that were incorrectly transcribed by comparing the transcribed text to the reference text. A lower WER indicates better performance, as it means fewer transcription errors.
CER (Character Error Rate): Similar to WER, the Character Error Rate measures the accuracy of a speech recognition system at the character level. It calculates the percentage of characters that were incorrectly transcribed, again by comparing the transcribed text to the reference text. This metric is especially useful for languages where character-level precision is crucial, such as languages with complex scripts. A bit less important than CER (especially in Dutch), because the meaning of the word will probably remain in tact.
We decided to run our benchmarks against these publicly available models:
Step 2: Extracting Data
After deciding on which data to extract, we had to find a way to automate the information extraction.
We chose on self-hosting a version of LLAMA in our own AI Platform to manage auto-scaling and so forth.
This way we could send our AI a CV-file and have it return all required data as a JSON object.
Ending up with a CSV with approximately 13.000 CV-data, including the actual selling rate.
Step 3: Building the model
We built our model using a neural network in Pytorch. What we noticed is that predicting a number, being the rate in euros, from data that does not include euro's or whatsoever is quite difficult.
Our first attempt ended up looking something like this:
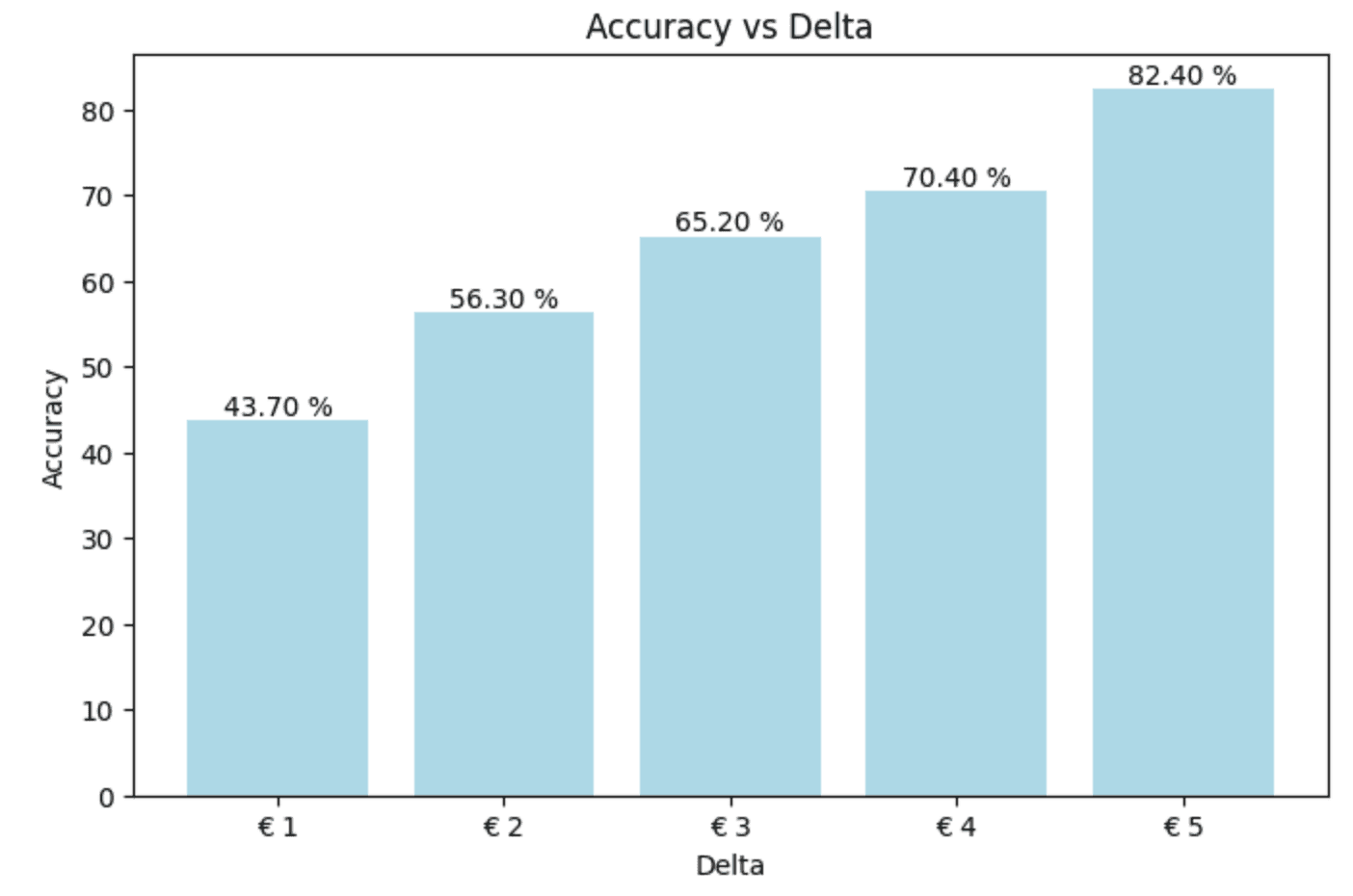
Not very good. This graph means that we only have an accuracy of 43,70 % with a delta of 1 euro. That means we're not very close to the actual results.
One strategy to improve your model is to add a value that kind-of correlates with the result you want. That would be the selling price in our case. Yet we can't include the selling price in our training that because then we'd need the rate to predict... the rate.
We chose to go for a grouping strategy. This means you group your training data based on a few parameters. Let's say age, department and degree. Then we add the average of that grouping to our training data.
So we add one parameter:
Start Year (when the individual started working)
Age (or date of birth)
Amount of employments
Department (.NET, Java, ...)
Degree
Employment (Payroll or contractor)
Province (Antwerp, East-Flanders, ...)
Average rate for people with the same start year, age and degree.
The average can easily be retrieved when doing the actual prediction. Let's retrain our model and check the results.
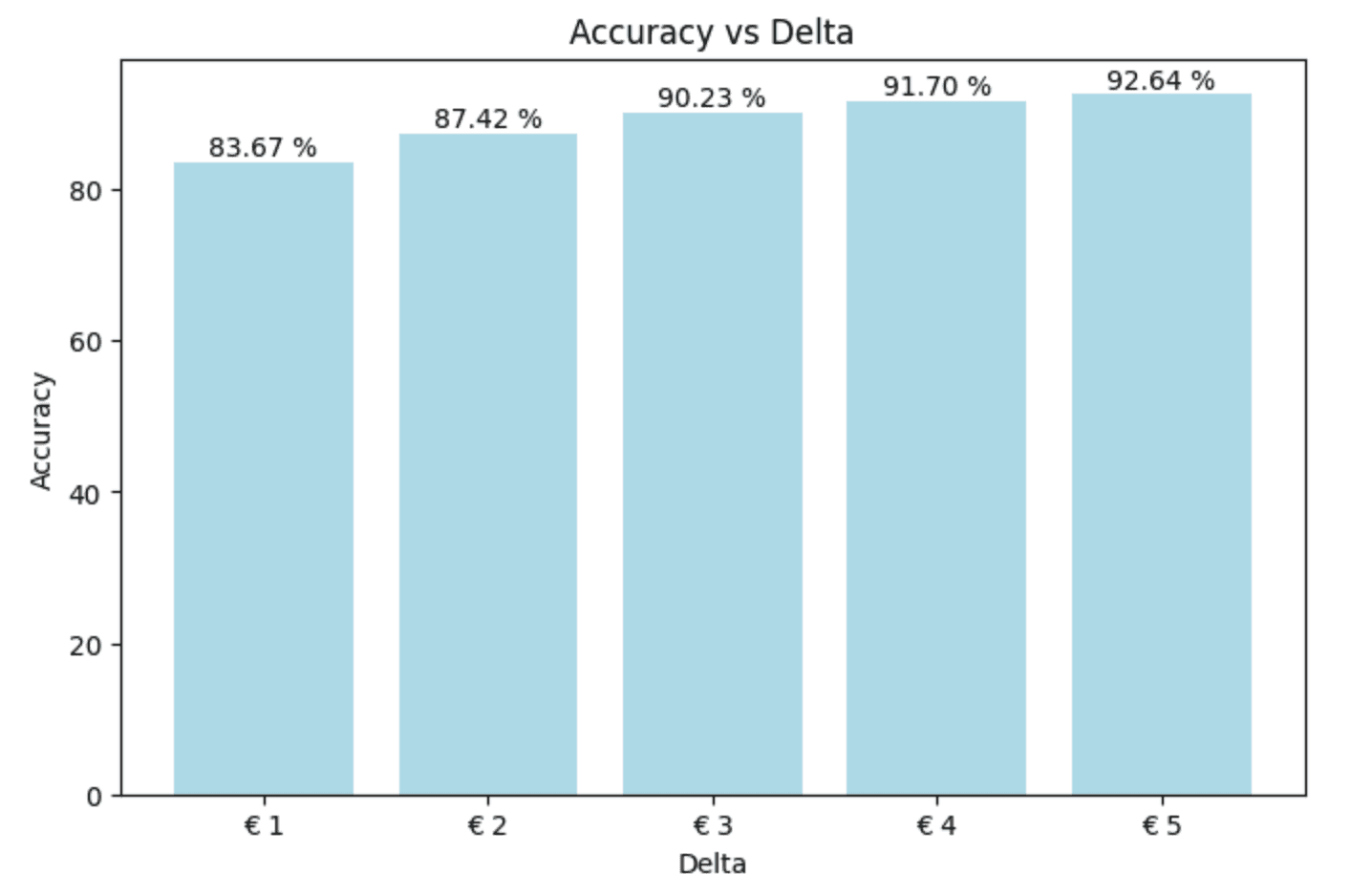
Bang! Much better. This means we can now predict a consultant's rate with a delta of 1 euro with an accuracy of almost 85 %.
Interested in getting your own rate prediction model or similar? Get in touch!

