Building an On-Premise Private AI Platform: A Modern Blueprint for Enterprises
Building an On-Premise Private AI Platform: A Modern Blueprint for Enterprises
In the era of generative AI, enterprises are eager to leverage AI capabilities on their own terms – with full control over data, compliance, and infrastructure. An on-premise private AI platform allows organizations to harness large language models (LLMs) and AI workflows within their own data centers or private cloud, avoiding the risks of sending sensitive data to third-party services. This article provides a forward-looking blueprint for building such an on-prem AI platform. We will outline a modern reference architecture built on a foundation of Postgres (EDB), Red Hat OpenShift AI, and open-source LLMs. We will also discuss the critical role of a central AI platform team for governance, how to implement secure Retrieval-Augmented Generation (RAG) pipelines with enterprise knowledge, best practices for document processing and integration with enterprise systems, the importance of observability, and why containerization, MLOps, and orchestration frameworks (like LangChain or LlamaIndex) are essential for sustainable growth.
By the end of this article, CIOs, CEOs, and enterprise architects will have a clearer vision of how to make on-prem AI a reality in a secure, scalable, and governed manner – and how Intellua and the Tech Tribes group can help along that journey.
A Modern On-Prem AI Reference Architecture (Postgres + OpenShift + Open LLMs)
At the core of a modern on-premise AI platform is a robust, scalable architecture that integrates data storage, model serving, and orchestration. The reference stack we recommend brings together EDB Postgres (with the pgvector extension) as a unified database for both traditional data and vector embeddings, Red Hat OpenShift AI as the enterprise AI/ML platform, and open-source LLMs deployed within your environment. This combination ensures you can store and retrieve knowledge efficiently, run and fine-tune AI models on secure infrastructure, and do it all without sending data outside your firewall.
Postgres (EDB) with pgvector – the unified knowledge store: EDB Postgres, enhanced with the pgvector extension, allows you to store high-dimensional vector embeddings (numerical representations of text) directly in a relational database. This means your enterprise knowledge base – documents, manuals, intranet pages, etc. converted into embeddings – can reside in the same trusted Postgres environment as your other data. By using Postgres as a vector database, you eliminate the need for a separate proprietary vector store, reducing complexity and keeping all data under unified management. Postgres handles semantic search via vector similarity queries, which is the backbone of retrieval-augmented generation (more on RAG later). In short, Postgres + pgvector provides a single source of truth for both structured data and unstructured embeddings, streamlining AI development and enabling powerful semantic search on your private data.
Red Hat OpenShift AI – the AI/MLOps platform: OpenShift AI (part of Red Hat’s AI portfolio) extends the Kubernetes-based OpenShift Container Platform with specialized tools for AI. It offers a comprehensive platform to manage the entire lifecycle of AI models (both traditional ML and generative LLMs) across hybrid cloud or on-prem environments. With OpenShift AI, you get built-in support for Machine Learning Operations (MLOps) and even emerging LLMOps practices. This means your data science teams can use familiar workflows (Jupyter notebooks, model training jobs, etc.), and when models are ready, the platform makes it easy to containerize and deploy them for production serving. Crucially for an on-prem solution, OpenShift AI provides the orchestration to automate data ingestion, embedding generation, and model deployment pipelines. It integrates with hardware accelerators (GPUs) and supports the tools and frameworks your teams use (from TensorFlow/PyTorch to NVIDIA’s AI stack). In our architecture, OpenShift AI acts as the central control plane: orchestrating AI workloads, ensuring they run reliably on the underlying infrastructure, and managing resources and scaling.
Open-Source LLMs – models under your control: To truly enable a private AI platform, enterprises are turning to open-source LLMs that can be run on-premise. Models like Meta’s LLaMA 3.3, Falcon, GPT-J, or Dolly 2.0 are examples of powerful LLMs that can be used without sending data to an outside API. These models (often with tens of billions of parameters) can be deployed within containers on OpenShift, either on bare-metal servers with GPUs or on specialized AI hardware, ensuring data never leaves your environment. Open-source LLMs have improved dramatically and can rival the quality of proprietary models for many tasks – all while giving you full control over the model parameters and the ability to fine-tune on your own data. For example, Meta’s LLaMA 3.3 is an open LLM that has been trained on over 2 trillion tokens and is available for commercial use. Enterprises can fine-tune such models on their domain-specific data and serve them internally. The benefit is twofold: (1) privacy – sensitive queries and content are processed locally, not sent to a third party; and (2) customization – you can optimize the model for your industry or jargon. As a recent case study, Dell tested LLaMA for on-premises AI workloads, highlighting that running generative AI on-prem is now quite feasible with the right hardware (GPUs) and software stack. In our architecture, these open LLMs would be containerized (using Docker/Podman images) and deployed via OpenShift’s model serving capabilities or custom inference servers.
Tying it together – Reference flow: The synergy of Postgres+pgvector and OpenShift AI becomes clear in a typical workflow: internal documents and knowledge are embedded into vectors and stored in Postgres; OpenShift AI orchestrates the embedding generation jobs (using, say, a transformer model to create embeddings) and then deploys the LLM that will utilize those embeddings. When a user or application query comes in, an API call is made to a service (running on OpenShift) that performs a vector similarity search in Postgres to fetch relevant context, and then queries the LLM to get a answer grounded in that context. This architecture ensures your proprietary data enriches the AI’s responses – all behind your firewall. It’s a future-proof setup: as newer open-source models or tools emerge, they can be slotted into this architecture (thanks to the flexibility of Kubernetes/OpenShift and standard interfaces). The result is an on-prem AI platform that is scalable, secure, and under your governance – enabling use cases from intelligent chatbots to autonomous agents that leverage enterprise data.
The Central AI Platform Team: Governance, Control, and Trust
Standing up the technology is only part of the equation. Equally important is establishing a central AI platform team – a cross-functional team that acts as the steward and gatekeeper of AI capabilities within the enterprise. This team (sometimes analogous to an AI Center of Excellence or platform engineering team) is responsible for ensuring that AI models are used safely, efficiently, and in compliance with organizational policies. In our experience, having a dedicated platform team is critical to scale AI across an enterprise with consistency and trust.
Key responsibilities of the AI platform team include:
Model Access Management: The team manages a catalog of approved AI models (foundation models, fine-tuned versions, etc.) that are available for internal use. They control who can access which models and ensure that any usage of external models or APIs meets security guidelines. For instance, if different business units want to leverage an LLM, the platform team might provide a central API or gateway to those models rather than everyone calling external services directly. By routing all model consumption through a controlled gateway, they can enforce standards and prevent unvetted models from being used in production. This model access control also involves maintaining versioned model checkpoints and governing when a new model version is promoted to production.
API Governance and Integration: The platform team often exposes AI capabilities via internal APIs or microservices. They define API standards (REST/gRPC endpoints, request/response formats) for accessing models, so that application teams can easily integrate AI into .NET applications, web apps, or other systems. Crucially, they also enforce rate limits, authentication, and authorization on these AI APIs – ensuring that usage is tracked and that only authorized systems can call high-powered models. Governance here means treating AI models as products internally, complete with usage policies. For example, Microsoft’s best practices suggest that developers “build and test, and we (the platform team) do all the rest” – highlighting how platform engineering provides the secure scaffolding so developers can just plug in AI.
Observability and Monitoring: A central AI platform team sets up robust observability for all AI services. This includes collecting metrics like model invocation counts, latency, throughput, and even LLM-specific metrics such as prompt lengths or token usage. Logging is enabled for all requests and responses (with appropriate privacy measures) so that there’s an audit trail of how the AI is being used. They monitor these logs for anomalies – for example, a sudden spike in errors or a usage pattern that might indicate misuse. In practice, this could mean using enterprise logging and monitoring tools (like Elastic Stack, Prometheus/Grafana, etc.) or specialized AI observability tools to track performance. For compliance and debugging, the team ensures every API call to a model is logged with user/app identity, timestamp, inputs/outputs. These audit trails are essential in industries with strict regulations or for investigating any problematic outputs.
Privacy and Compliance Enforcement: The platform team works closely with security and compliance officers to enforce data privacy rules. Since the AI platform deals with potentially sensitive data (e.g., feeding customer data to an LLM), the team must implement controls to prevent data leaks. On an on-prem platform, this starts with keeping all data local – no “phoning home” to external services. Additionally, the team may implement features like data redaction or anonymization in logs (to avoid storing raw PII in plain text), encryption at rest and in transit for all data and embeddings, and ensure that model training data and outputs adhere to privacy policies. If certain data is highly sensitive, the platform team might restrict which models can be applied to it (for example, only allowing a highly secure internal model to handle HR data vs. a more general model for public data). They also keep track of model licenses (for open-source models) to ensure compliance with their terms of use, and they validate that model outputs aren’t inadvertently breaching copyright or compliance rules.
Auditability and Transparency: The team is responsible for providing transparency reports and tools. For instance, they might build an internal portal where stakeholders can see which models are in use, what data sources have been ingested, and summary statistics of model performance. In case of any AI-generated mistake or incident, the platform team can audit what happened: which model produced it, with what prompt, and what data was referenced. This level of traceability builds trust with business units and external auditors alike. As Amazon describes it, you need policy, guardrails, and mechanisms for responsible AI – the platform team implements those guardrails (like content filters or prompt validations) and mechanisms (like routine audits of outputs for bias or errors).
In summary, the central AI platform team ensures operational excellence of AI in production: they mitigate risks, enforce standards, and optimize performance. By doing so, individual development teams can focus on innovating with AI features, knowing the platform team has their back on compliance and reliability. This organizational model – “you build it, we run it” – is key to scaling AI across many teams. Just as DevOps practices matured with platform engineering for cloud, AI needs platform engineering for on-prem AI to truly succeed.
Secure Retrieval-Augmented Generation (RAG) with Enterprise Knowledge
One of the most powerful patterns to emerge for enterprise AI use cases is Retrieval-Augmented Generation (RAG). RAG allows LLMs to give factually grounded answers by retrieving information from a knowledge repository (your enterprise content) and using it as context for generation. In an on-prem environment, implementing RAG securely means your internal documents and data sources can be harnessed by the LLM without exposing any data to the outside world. Let’s break down how to build a secure RAG pipeline step by step.
How RAG works (in a nutshell): Instead of relying solely on an LLM’s built-in knowledge (which might be outdated or generic), RAG supplies the LLM with relevant pieces of your data at query time. There are two phases: a retrieval phase – where the system finds relevant documents or snippets from a knowledge base; and a generation phase – where the LLM produces an answer using both the query and the retrieved data. By doing this, the LLM’s response is “augmented” with real, up-to-date information, often resulting in more accurate and context-specific answers. In an enterprise, that knowledge base could include policy documents, product manuals, wikis, SharePoint content, support tickets – essentially the trove of unstructured information that employees accumulate.
Key components of a RAG pipeline (on-prem):
Document Ingestion & Embedding: First, you ingest the enterprise content into the system. Documents (PDFs, Word files, wiki pages, etc.) are read and broken into chunks (e.g., splitting each document into paragraphs or sections). Each chunk of text is then run through an embedding model – likely a sentence-transformer or similar neural model – to generate a vector representation of that text. These vectors capture the semantic meaning of the text. In a secure on-prem setup, this embedding model can be an open-source model (such as HuggingFace’s transformers) running locally, so even this step doesn’t call any external API. The resulting embeddings, along with references to the source document, are stored in the vector database – here, that’s Postgres with pgvector. Using Postgres for this is advantageous because it supports ACID transactions, role-based access control, and encryption just like any relational data store, meaning your vector data gets enterprise-grade security features out of the box. The platform team might schedule this ingestion as a batch job (for a large corpus) or set up continuous ingestion pipelines for new or updated documents.
Vector Database (Knowledge Base): The embeddings in Postgres essentially form your enterprise knowledge index. Each vector is stored alongside metadata – such as the document ID, section title, keywords, and perhaps access control tags. One best practice is to also store a short text summary or the actual text chunk alongside the vector in the database. This way, when you retrieve by vector similarity, you immediately get not just the vector IDs but the actual text passages that can be given to the LLM. The Postgres
pgvectorextension supports efficient similarity search (like cosine distance or inner product search) and can be indexed for performance. Because it’s all in Postgres, you can leverage SQL for filtering: e.g., only search within documents tagged as “finance” if the user is asking a finance-related question, or enforce row-level security so that, say, HR documents aren’t retrieved for a query from a sales portal user. Security tip: Ensure that the vector DB only returns results the requesting user is permitted to see. This might involve storing user-document permissions and filtering the similarity search by user context – adding another layer to RAG to prevent information disclosure.Retrieval Phase: When a user poses a question (through whatever interface – a chat UI, an application feature, etc.), the system first takes the query and generates its embedding (using the same embedding model as above). This query embedding is then used to perform a vector similarity search in the Postgres vector table. The database returns the top k most similar chunks of text, which are presumably the most relevant pieces of knowledge for that query. For example, if the user asked about “our warranty policy on product X,” the search might return a couple of chunks from the product X warranty PDF in the knowledge base. These retrieved texts are then consolidated (perhaps truncated or ranked further if necessary) to serve as context.
Generation Phase: Now the original question along with the retrieved context snippets are fed to the LLM. Because everything is on-prem, this means the query and the documents are sent to your local LLM instance (no data leaves the premises). The prompt might be constructed like: “Using the information below, answer the question: [User’s question]\n\n[Retrieved document excerpts]”. The LLM will generate a response that hopefully cites or draws from that provided information. Since the model has the relevant facts from your knowledge base, it doesn’t have to rely on potentially hallucinated knowledge – it can quote the actual policy or give the precise figures from the document. This greatly increases the accuracy and trustworthiness of the output. Essentially, the LLM becomes a fluent communicator that grounds its answers in your proprietary data.
Response and Feedback: The answer is returned to the user, often with references (some RAG implementations even highlight which document or page provided the info). A feedback mechanism can be put in place – e.g., the user can mark if the answer was helpful or not, feeding into an improvement loop (perhaps flagging irrelevant retrievals or suggesting fine-tuning data for the model later). Importantly, all this happened without any external API calls, meaning data security was maintained throughout.
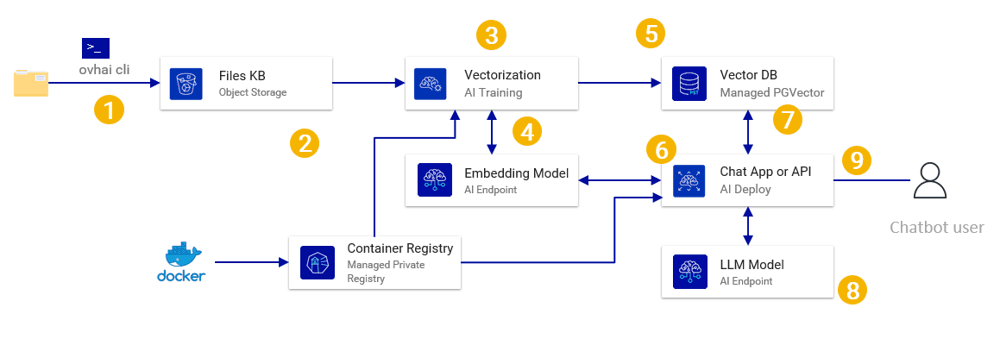
Figure: Example Retrieval-Augmented Generation (RAG) workflow in an on-prem environment. Enterprise files are ingested and stored as embeddings in a vector database (Postgres with pgvector). At query time, the user’s question is vectorized and relevant content is retrieved via similarity search, then fed into an LLM to generate a context-grounded answer.
Ensuring Security in RAG: A few best practices are worth highlighting to keep RAG pipelines secure and effective:
Use local models for embedding and LLM: As mentioned, choose or fine-tune models that can run locally. There are many open-source embedding models (e.g., sentence transformers) and several open LLMs that can run on modest GPU hardware if properly optimized (or larger GPU clusters for bigger models). This avoids external calls. Some organizations even deploy embedding models on CPU if GPUs are scarce, accepting a trade-off in speed to maintain privacy.
Access control for content: Integrate your authentication/authorization system with the RAG pipeline. For example, if certain documents are confidential and only accessible to HR, ensure the retrieval step knows the identity of the user and filters out vectors the user shouldn’t see. This might involve partitioning the vector index by clearance level or tagging embeddings with permissions.
Audit trails: Log which documents were retrieved for each query. This not only helps in debugging and improving the system (seeing if irrelevant info was fetched), but also in compliance – if someone asks a question and gets a piece of information, you have a record of what source content influenced that answer.
Chunking strategy: Chunk size matters. If chunks are too large, you might include a lot of irrelevant text; if too small, you might lose context. A common strategy is to chunk by paragraphs or sections and possibly allow some overlap. Ensure that chunking is done in a way that doesn’t split sentences awkwardly. The target LLM’s context window (e.g., 4k tokens) will determine how many chunks you can feed it at once, so tune your chunk size and number of retrieved pieces accordingly.
Monitoring and iteration: RAG is not “set and forget.” Monitor the quality of answers. If users are frequently getting “I don’t know” or incorrect answers, you may need to add more content to the knowledge base, adjust your embedding model, or even fine-tune the LLM to better handle your domain. Periodically re-run embeddings for content if your embedding model or content updates (embedding drift can affect results).
With a secure RAG system in place, you unlock use cases like internal chatbots that can answer any employee query by referencing internal knowledge, or expert assistive tools that help your support staff find answers in thousands of pages of documentation in seconds. All this happens on-premise, meaning the competitive knowledge of your business stays confidential while your employees benefit from AI’s speed and intelligence. RAG truly brings the promise of generative AI to enterprise data in a safe and practical way.
Document Processing, Summarization, and Enterprise Integration
Feeding your enterprise knowledge to AI – and getting useful insights out – requires careful handling of documents and thoughtful integration into the systems people use every day. In this section, we cover best practices for document processing (how to prepare and summarize content for AI), as well as tips for integrating AI capabilities into existing enterprise applications (be it a .NET application, an on-premise intranet, or other platforms).
Document Processing 101: Enterprises deal with a variety of documents: long reports, PDFs with mixed text and images, spreadsheets, slide decks, wiki pages and more. Preparing these for consumption by AI involves a few steps:
Digitization and Text Extraction: If some documents are scans or images (think of signed contracts or legacy documents), use OCR technologies to extract text. This ensures even non-text PDFs become part of the searchable knowledge base.
Cleaning and Preprocessing: Remove boilerplate or irrelevant sections (like footers on every page, or navigation menus from wiki HTML) that don’t carry useful information. Normalize text (fix encoding issues, expand abbreviations) as needed. This increases the quality of embeddings and summaries.
Chunking and Metadata: As discussed in RAG, chunk documents into semantically coherent pieces. Preserve references – for each chunk, know which document and section it came from. Store metadata like title, author, date, and tags (department, project, etc.). This metadata can be used later for filtering and also for crafting better prompt context (“This excerpt is from Project Apollo Design Spec, last updated 2022”).
Summarization and Multi-level Indexes: For very large documents or sets of documents, it can help to create summaries. An effective practice is hierarchical summarization: for example, break a 100-page document into chapters, summarize each chapter with an LLM, and store those summaries. You could even summarize the summaries to get a high-level outline. These summaries can be stored as additional context in your knowledge base. They serve two purposes: (1) They can be retrieved via RAG when a broad question is asked (the LLM can use the summary to answer general questions or to navigate to relevant sections); (2) They speed up understanding – sometimes presenting the user a short summary is useful in itself. Modern LLMs can do a decent job at summarizing while preserving key facts, especially if fine-tuned for your domain. Always review critical summaries with a human in the loop to ensure accuracy.
Avoiding context overload: It might be tempting to stuff an entire document into an LLM prompt (“stuffing” method), but that doesn’t scale for long documents. Instead, prefer the retrieve-then-summarize approach (RAG) or use iterative refinement. Google Cloud suggests techniques like “map-reduce” summarization: break the text, have the model summarize pieces, then summarize the summaries. These techniques are valuable to produce an accurate summary of a long text that an LLM with limited context window otherwise couldn’t handle in one go.
Use case – Document Summarization: Imagine an employee needs to quickly understand a 50-page policy document. With the above setup, you could provide an AI service that, on demand, generates a summary or answers specific questions about that document. In fact, summarization was explicitly identified as a valuable internal use case by VMware’s AI initiative – enabling employees to digest company-private content more efficiently. By integrating such summarization tools on-prem, you maintain confidentiality (the documents aren’t sent to external APIs) and improve productivity.
Integrating AI with Enterprise Systems: It’s not enough to have AI in a silo; it should integrate where your users work. Here are some strategies for common platforms:
.NET Applications: Many enterprise apps are built on the .NET stack (web apps in ASP.NET, desktop apps in C# WPF, etc.). To integrate AI, you can either call your AI platform’s REST API from the .NET code, or use an SDK if available. Microsoft has introduced Semantic Kernel, an open-source SDK that helps integrate and orchestrate AI models within .NET applications. Semantic Kernel allows .NET developers to call LLMs (OpenAI, Azure OpenAI, or local) and even chain prompts and tools in a robust way. It abstracts prompt handling, memory (storing context), and planning so that developers can seamlessly embed AI features. For example, a CRM system built in .NET could use Semantic Kernel to generate a summary of the latest customer interactions or suggest next actions, by querying an internal LLM with relevant data. Even without Semantic Kernel, a lightweight approach is to expose your on-prem LLM as a REST service and then simply use HttpClient from C# to get AI outputs. The key is to integrate AI calls in the existing workflow – e.g., a button “Summarize this document” in a document management system, or an AI-assisted search in an intranet portal.
MediaWiki and Knowledge Bases: Platforms like MediaWiki (often used for corporate knowledge bases) can benefit greatly from AI integration. One approach is API Integration, where the wiki calls an AI service via API to do things like answer questions or generate content suggestions. This requires minimal change to the wiki but means you need that AI service running (which our platform provides). Another approach is direct hosting or extension – essentially running the LLM on the same server or as an extension to MediaWiki. This is more complex but yields lower latency and data doesn’t leave the wiki’s server. For instance, an extension could intercept search queries on the wiki: instead of just keyword matching, it sends the query to the RAG pipeline which returns a rich answer with sources. The WikiTeq guide on integrating LLMs into MediaWiki suggests identifying clear use cases first (like assisting editors with writing, or providing a Q&A chatbot for wiki content) and then choosing integration methods accordingly. In practice, many organizations start with a simple chatbot interface hooked to their wiki content – basically a conversational search that uses RAG on the wiki’s data. This can be done with a small web app that interfaces between the wiki and the AI backend.
Other Systems (.docx, CRM, etc.): For office documents, one can integrate with tools like Office add-ins (imagine an “AI summarize” button in Word that calls your on-prem AI). For ERP/CRM systems, use their extensibility (most have API or plugin frameworks) to embed AI. An interesting real-world example is companies building internal coding assistants that integrate with their private Git repositories and IDEs, running wholly on-prem. The general pattern is: identify where employees could use AI assistance (writing, reading, decision support), and then use the platform team’s APIs to plug AI in there.
APIs and Microservices: A flexible way to integrate everywhere is to build microservice endpoints for specific tasks. For instance, an endpoint
/ai/summarizethat accepts a document and returns a summary, or/ai/answerthat accepts a question and context. Internal developers can then mix and match these in various apps. This is where API governance (discussed earlier) is important, so that all calls are funneled through proper monitored channels.
Best Practices Recap: When deploying AI features into enterprise workflows, always test thoroughly. Unlike deterministic software, AI can sometimes produce unexpected outputs – you want to ensure the suggestions or answers it provides in, say, your IT helpdesk system are accurate and appropriate. It’s wise to start with a pilot group, get feedback, and perhaps keep a human fallback option initially (“Not sure? Click here to escalate to a human”). Moreover, keep the user experience in mind: AI should augment and simplify work, not confuse users. For example, if your AI gives a confidence score or multiple suggestions, present them in a clear way. Leverage observability here too – instrument the integration to log how often AI is used and its outcomes (e.g., did the user accept the suggestion or ignore it?). This data can guide further tuning.
By processing documents smartly and weaving AI into existing systems, you effectively upgrade your enterprise’s collective intelligence. Employees can get instant answers from thousands of pages of documentation, content creators can get first drafts or summaries, and decision-makers can query data in natural language. All of this is done while maintaining control: the content stays in your databases, and the AI is a trusted assistant within your digital walls.
Observability: Logging, Monitoring, and Audit Trails for AI
In traditional software, we rarely deploy anything mission-critical without monitoring and logs – the same must hold true for AI systems. In fact, observability is even more crucial for AI because of the non-deterministic nature of model outputs and the potential for surprising behavior. A robust observability setup for your on-prem AI platform will ensure you can track performance, detect issues, and meet compliance requirements.
Logging Every Interaction: At a minimum, your AI platform should log every request and response that flows through it (with appropriate scrubbing of sensitive data when needed). For an LLM service, this means logging the prompt (input) and the output, along with metadata like timestamp, user or application ID, and which model was used. These logs become your audit trail. They answer questions like: “Which information did the AI provide to user X last Wednesday?” or “Has this confidential term ever appeared in an AI output?”. Logging all API calls to the model with user context is a recommended best practice, as noted by AWS’s guidelines for their Bedrock service. In our on-prem scenario, we might not have something like CloudTrail, but we can achieve similar logging with centralized log management tools.
Metrics and Performance Monitoring: Treat your AI models as you would a web service or database in production: monitor key metrics. These include system metrics (CPU/GPU utilization, memory usage of model servers), performance metrics (requests per second, request latency), and AI-specific metrics such as: average prompt length, average response length, number of tokens processed per request (which influences compute cost), cache hit rates (if using a caching layer for repeated queries), etc. It’s also useful to track the quality in some way – for example, if you have a thumb-up/down feedback from users on answers, log those counts. Modern AIOps dashboards can integrate such metrics to give you a live health view. If using OpenShift, you can tap into its monitoring stack (Prometheus/Grafana) to scrape metrics from your AI services. Custom metrics can be exposed via an endpoint by your model server. Keep an eye on error rates too – e.g., how often does the LLM refuse to answer or produces an error. Spikes in errors or latency should trigger alerts.
Observability for RAG and Pipelines: For multi-step pipelines (like RAG), it’s important to monitor each stage. You’d want to know if the embedding service is slowing down or if the vector search is taking too long or returning too many/few results. Monitoring the vector DB (Postgres) performance is also key – index bloat or slow queries will directly affect user experience. If you see that certain queries frequently return zero results (maybe because the knowledge base is missing info), that’s a signal to improve content coverage.
Tracing: In a microservice or distributed workflow environment, implementing distributed tracing can be very beneficial. For instance, a user query might flow through an API gateway, to a retrieval service, to a model service. Using tracing (with something like OpenTelemetry), you can trace a single request through all these components, which helps in debugging latency issues or failures. It’s particularly helpful when an end-user reports “the AI is slow” – tracing might reveal the bottleneck (maybe the vector DB query is slow, or maybe the LLM took 5 seconds to generate). With tracing, you can pinpoint which segment took how long.
Auditing and Compliance Checks: Audit logs shouldn’t just exist; they should be reviewed. The platform team can implement automated checks on the logs. For example, run a script to flag if any output contains certain sensitive keywords or appears to violate policies. These can be basic (regex-based) or advanced (even using another AI to scan outputs for problematic content). Who accessed what is also an audit angle – ensure your logs can answer if a particular user tried to get certain info via the AI. For compliance, if your industry requires data retention or deletion, set policies for logs too. Maybe you keep full logs for X days, and then only keep anonymized summaries for longer, depending on regulations.
Continuous Learning from Logs: Observability isn’t only about catching problems; it’s a goldmine for improvement. By analyzing usage logs, you can discover trends: which questions are commonly asked that the AI couldn’t answer? Which documents are frequently retrieved? Are users trying to use the AI for tasks it’s not tuned for? This insight can feed into your model fine-tuning or prompt engineering efforts. Perhaps you find that many users ask questions about “policy ABC” and the answers are lengthy – you might decide to fine-tune the model on that policy document or create a special summary to improve those interactions.
Example of Observability in action: Let’s say you deploy a coding assistant LLM internally for developers. Through monitoring, you notice that every day around 9-10 AM, the latency jumps and some requests time out. Investigating the metrics, you see GPU utilization is maxed out. Tracing shows a surge of simultaneous requests – likely many developers logging in and asking for code suggestions at the start of the day. With this data, you decide to deploy a second replica of the model server to load-balance, or schedule a warm-up of the model in memory at 8:55 AM to handle the spike. Without observability, you’d rely on word-of-mouth (“the tool is slow in the morning”) and guesswork. With it, you have concrete data to make decisions and improve reliability.
AWS’s well-architected guidelines emphasize “implement observability for actionable insights” as a top design principle. For an on-prem platform, the tools might be different, but the spirit is the same. We need logs, metrics, and traces to gain transparency into the AI’s operation and to provide control through that transparency. In practice, enterprises might integrate AI platform logs into their existing SIEM (Security Information and Event Management) systems as well, so that security teams can treat AI events like any other critical system events.
In summary, invest in observability from day one of your AI platform. It will pay off in uptime, performance, and trust. Stakeholders will feel more at ease knowing there’s a proverbial “black box recorder” for the AI – if something goes wrong, you can investigate it. And your team will sleep better at night with alerts set up for the AI services, just like they have for databases or websites. AI might seem magical, but running it is an engineering task like any other – instrument it, monitor it, and continuously improve it.
Containerization, MLOps, and Orchestration: The Key to Sustainable AI
As your enterprise AI efforts grow, so will the complexity of managing models, experiments, and deployments. Containerization, MLOps practices, and orchestration frameworks are the trifecta that ensures your AI platform can scale sustainably and adapt to new challenges. Let’s unpack why each of these is essential:
Containerization for Portability and Consistency: By packaging models and AI services into containers (e.g., Docker or OCI containers), you achieve a consistent runtime that can be deployed anywhere – on developer laptops, on your on-prem Kubernetes cluster (OpenShift), or even on edge devices. Containers encapsulate the model binaries, dependencies, and environment in a reproducible way. This eliminates the “works on my machine” problem when moving from research to production. For on-prem AI, containerization is especially useful because you might have a mix of hardware (GPU nodes, CPU nodes) and environments (dev, test, prod clusters). With containers, you can move a workload to where the resources are available. In our reference architecture, OpenShift is fundamentally a container orchestration platform, so everything – the LLM serving microservice, the embedding job, the vector DB – runs in containers. This also eases upgrades and rollbacks: for example, if a new version of an open-source LLM comes out with improvements, your team can build a new container image for the model server and deploy it alongside the old one, shifting traffic gradually. If issues arise, roll back to the previous container image.
Containerization also plays a role in security and efficiency: you can isolate AI services, limit their resource usage, and schedule them effectively on physical nodes. Technologies like NVIDIA Docker allow containerized access to GPUs which is crucial for model workloads. Additionally, if you adopt a multi-cloud or hybrid stance, containers give you the flexibility to burst to cloud or migrate environments without refactoring the entire codebase.
MLOps: Treating Models like Products with CI/CD: MLOps is the extension of DevOps to the ML world – it encompasses practices from training to deployment to monitoring of models. Embracing MLOps in your on-prem platform means you set up pipelines to retrain or fine-tune models, automated testing of model performance, and continuous delivery of model updates. For example, if you fine-tune a classifier or an LLM on new data, an MLOps pipeline would: train the model (perhaps on a schedule or when new data is available), evaluate it against a validation set (to ensure it’s not degraded), and if it passes certain metrics, automatically deploy the new model version to a staging environment. With approval, it then goes to production. This is analogous to CI/CD for software but with some ML-specific steps (like data versioning and model evaluation). OpenShift AI facilitates these workflows by integrating tools for model build and deployment, but you can also leverage open-source tools like Kubeflow, MLFlow, or Argo Workflows for orchestrating these steps.
Why is this important? Because without MLOps, your data scientists might manually run training scripts ad-hoc, resulting in inconsistent model versions and a lot of hassle to deploy improvements. MLOps brings discipline: models are packaged (often as Docker images as discussed), versions are tracked (with metadata about data and training configs), and there’s a registry (like a model registry) to promote models from “candidate” to “production”. Additionally, MLOps handles rollbacks if a new model underperforms. By establishing this, you ensure that as your use of AI grows (from one model to dozens), you can manage it without a proportional explosion of manpower. In fact, Gartner’s observation that only ~54% of AI projects make it from pilot to productionoften ties back to lack of such operationalization. By adopting MLOps early, you avoid being part of that statistic – you create a repeatable path for any AI project to go live successfully and stay maintained.
From MLOps to LLMOps: Large Language Models introduce some new challenges – hence the term LLMOps emerging. LLMOps includes prompt management, chaining of model calls, and dataset management for fine-tuning. It also deals with aspects like prompt versioning (if you tweak how you prompt the model in production), and managing feedback loops (collecting user feedback on outputs and possibly retraining on that). Orchestration frameworks, which we’ll discuss next, are part of addressing these challenges.
Orchestration Frameworks (LangChain, LlamaIndex, etc.): These have become popular because building AI applications often involves connecting multiple pieces: an LLM here, a vector store there, some logic to format prompts, maybe tools the LLM can call (like calculators or databases). LangChain is a framework that helps developers “chain” together LLM calls and integrate with data sources (like vector databases for RAG) via a standard interface. LlamaIndex (formerly GPT Index) is another framework focused on connecting LLMs with your external data in flexible ways. Using such frameworks can significantly speed up development of AI-powered features. Instead of writing a lot of boilerplate code to query the vector DB, chunk context, call the LLM, etc., LangChain provides abstractions (like Chains, Tools, Agents) to do that heavy lifting. This means your team can prototype and deploy complex AI applications faster, and maintain them more easily. For example, LangChain can let you define a Q&A chatbot in a few lines: you specify the LLM to use, the vector store to pull from, and LangChain handles constructing the prompt with retrieved docs, calling the model, and returning the answer. Under the hood, it’s orchestrating the calls we described in the RAG section. It even has features to manage conversational memory (so the bot can have multi-turn context).
Why is this essential for sustainable growth? Because as you scale use cases, you don’t want to reinvent the wheel each time. Tools like LangChain become part of your internal AI development toolkit. They also encourage best practices – for instance, LangChain makes it easier to implement things like prompt templates and guardrails, which otherwise each team might do inconsistently. Aleksandra Sidorowicz, in discussing MLOps vs LLMOps, notes that tools like LangChain have risen in popularity precisely because they simplify building LLM-powered apps with the needed components. An example she gives is a Q&A chatbot backed by a vector database – exactly our RAG scenario – which LangChain makes straightforward to implement.
Similarly, LlamaIndex provides an interface to build indices over your data and query them with natural language, abstracting the retrieval step nicely. These frameworks are open source and can be deployed on-prem (they’re just Python libraries, for instance), so they fit well into our architecture.
Container Orchestration: We can’t forget the orchestrator at the infrastructure level – Kubernetes/OpenShift itself. This ensures high availability and scaling. If demand for AI services increases, Kubernetes can spin up more pods (containers) of the model server. It can also restart pods that fail (which might happen if a model crashes). For scheduled jobs like nightly retraining, it can run batch jobs in isolated environments. Essentially, Kubernetes is the backbone that operationalizes the containers and MLOps processes.
Example – Continuous Improvement Cycle: Imagine your customer support bot that uses an LLM and RAG. In practice, new issues and answers are created by support agents every day. With a solid platform, you could schedule a daily pipeline: embed any newly added support Q&A documents into Postgres, and fine-tune your LLM on any confirmed correct Q&A pairs from the previous day (for example, if the LLM failed and a human answered, incorporate that). This pipeline would be containerized, orchestrated (maybe via Argo on OpenShift), and automated. As it runs, everything is monitored (MLOps), and the updated model is deployed seamlessly to production. This kind of virtuous cycle keeps the AI’s knowledge up-to-date and gradually improves it – and it’s only feasible in a sustainable way if you have the containerization + MLOps + orchestration scaffolding in place.
Governance via Orchestration: Another benefit – your platform team can bake in governance at the orchestration level. They can use Kubernetes admission controllers to ensure all AI containers meet security requirements (e.g., no running as root, only allow pulling images from trusted registry). They can enforce resource quotas so one team’s heavy model doesn’t starve others. Basically, all the benefits of cloud-native infrastructure and DevOps now apply to your AI workloads.
In conclusion, containerization, MLOps, and orchestration are the foundation for agility in enterprise AI. Without them, you might succeed in one project, but struggle to repeat that success broadly or maintain it over time. With them, you create an AI factory of sorts – ideas can quickly go from notebook to deployed service, and services stay reliable and continuously improved. It’s the difference between a one-off demo and a scalable AI platform that grows with your business needs.
Conclusion: Partner with Intellua to Make On-Prem AI Real
Building an on-premise private AI platform is a journey that combines cutting-edge technology with thoughtful governance. We’ve outlined how a modern architecture – leveraging EDB Postgres for unified data storage, OpenShift AI for robust model operations, and open-source LLMs for customizable intelligence – can empower your enterprise with AI while keeping you in full control. We’ve highlighted the necessity of a central AI platform team to enforce best practices, and delved into securing RAG pipelines, integrating AI into your everyday tools, and ensuring everything runs observably, efficiently, and safely. The path to on-prem AI can be complex, but with the right strategy and partners, it becomes not only feasible but highly rewarding.
Intellua, as part of the Tech Tribes group together with Kangaroot and HCS Company, is your trusted partner in this journey. We bring deep expertise in open-source technology, AI/ML engineering, and enterprise IT integration. Whether you need guidance in designing the reference architecture, hands-on help with deploying OpenShift AI and Postgres, or establishing the governance processes for your AI platform team, Intellua can help you every step of the way. We have experience in bridging the gap between innovative AI solutions and real-world enterprise requirements – ensuring that your on-prem AI platform is not just a bold experiment, but a sustainable, scalable asset driving your business forward. Let’s make on-prem AI real, together.
Ready to get started? Get in touch!
Want a solution like this?
Enter your email here and we'll get in touch with you.